Webの基礎
HTTP (Hyper Text Transfer Protocol)
HTTP は、 HTMLやCSSなどのリソースファイルを読み取るためのプロトコル(通信規則)。 HTTPは、クライアントとサーバーの間でデータを送受信するための規則を定めている。
クライアントは、ChromeやSafariなどのブラウザーの他にcurlなど様々なものがある。
サーバーは、ApacheやNginxのようなWebサーバーを使う、もしくはNode.jsのexpressなどのサーバーフレームワークを用いて作ることができる。
HTTP リクエスト
クライアントがサーバーに操作を要求する際に送信されるのがHTTP リクエスト。

メソッド (Method)
メソッドは、クライアントがサーバーに対して行いたい操作を示す。 以下のような種類があり大体以下のような意味である。
- GET
- HTMLファイルや画像などのファイルや、ユーザー情報などのデータを取得する。
- 情報を取得するだけで、サーバーのデータを変更しない。
- POST
- ユーザーが入力した情報をサーバーに送信する。
- 新しくデータを作成するなど、サーバーのデータを変更する。
- DELETE
- サーバーのデータを削除する。
- 他にはPUT、PATCHなどがある。
パス (Path)
どこにアクセスするかを示す。
/ で始まり、サーバー上のファイルやディレクトリを示す。
ヘッダー (Header)
リクエストに関する情報を含む。 以下はヘッダーの例。
- User-Agent (UA)
- リクエストを送信したクライアントの情報を含む。
- 例:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3 - この情報からWebサーバーは、リクエストを送信したクライアントがどのようなブラウザーを使用しているかを知ることができる。
- Authorization
- リクエストを送信するユーザーの認証情報を含む。
- 例:
Authorization: Bearar <認証情報> - Webサーバーは
<認証情報>を調べユーザーが認証されているかを確認する。
ボディ (Body)
省略可能。 POSTで送信するデータの本体など。
HTTP レスポンス
サーバーがクライアントに対して返すデータがHTTP レスポンス。

ステータスコード (Status Code) / ステータスメッセージ (Status Message)
HTTP レスポンスには、リクエストが成功したかどうかを示すステータスコードとその意味のステータスメッセージが含まれる。
よく見るステータスコード/メッセージは 404 Not Foundなどがあると思う。
ステータスコード/メッセージは以下のような意味がある。
- 1xx: 情報
- リクエストを受け取り、処理中。
- 2xx: 成功
- リクエストが成功した。
- 200: OK
- 3xx: リダイレクト
- リクエストを完了するために追加の処理が必要。
- 301: Moved Permanently (永続的に移動)
- 302: Found (一時的に移動)
- 4xx: クライアントエラー
- クライアントのリクエストに誤りがある。
- 存在しないページにアクセスした場合やログインしていない場合など。
- 400: Bad Request (リクエストが不正、またはサーバーが理解できない)
- 401: Unauthorized (認証が必要)
- 403: Forbidden (アクセス権がない)
- 404: Not Found (ページが見つからない)
- 5xx: サーバーエラー
- サーバーがリクエストを処理できない。
- サーバーがダウンしている場合など。
- 500: Internal Server Error (サーバー内部エラー)
ボディ (Body)
省略可能。 レスポンスに含まれるデータ。 ファイルの中身など。
URL
https://naotiki.me や https://google.com など私達が普段目にする「URL」。
実はURLは以下の図のように様々なパーツに分かれている。
 本節ではURLを各パーツごとに解説していく。
本節ではURLを各パーツごとに解説していく。
スキーム (Scheme)
 通常、私達が目にするWebサイトは
通常、私達が目にするWebサイトは
- HTTP
- HTTPS (安全)
のどちらかの方法(プロトコル)を通して配信されている。
スキームでは、httpやhttpsのようにどの方法を使用して通信しているかを示している。
現代において、インターネット上に公開されているWebページのほとんどはHTTPよりも安全なHTTPSを介して配信されている。
オーソリティ (Authority)
 スキームの次に続くのは ドメイン名 (Domain Name) とポート (Port)からなるオーソリティという部分。スキームとオーソリティは
スキームの次に続くのは ドメイン名 (Domain Name) とポート (Port)からなるオーソリティという部分。スキームとオーソリティは://で区切られている。
ホスト (Host) / ドメイン名 (Domain Name)
ホストは、HTTPサーバーがいるコンピューターを指す。
IPアドレスでもいいし、ドメイン名でもいい。
ドメインは naotiki.me や example.com のような文字列。
インターネット上で完全に一意な名前である。
レジストラから(クレジットカードやデビットカードがあれば)誰でも買える。
おすすめは Cloudflare。
開発時、自分のPC上でサーバーを立てる場合は 自身のコンピューターを指す、localhost や 127.0.0.1を使用する。
ポート (Port)
どのポートにHTTPリクエストを送信するかを示す。 HTTP(S)にはデフォルトのポートがあり、HTTPは80番、HTTPSは443番。 デフォルトのポートを使用する場合は省略することができる。
開発時には 8080 や 3000 などのポートを使用することが多い。
パス (Path)

初期のWebではサーバー上にある実際のファイルへのパスを示していたが、現在ではパスはWebサーバーによって処理される抽象的なものになっている。
「抽象的なもの」とは?
https://x.com /Naotiki13/status/1813753684838510978
実際のサーバーに/Naotiki13/status/1813753684838510978というファイルがあり、そこに
実績解除YubiKey洗濯と書かれているわけではない。 サーバーはリクエストにあるこのパスを見て、「Naotiki13」さんのポスト「1813753684838510978」を見たいんだなと解釈しデータベースからデータを取得し、返している。
クエリパラメーター (Query Parameter)
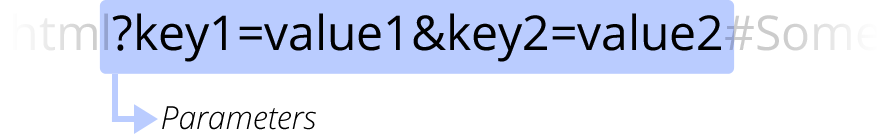 Webサーバーに提供される追加の引数のようなもの。なんの値かを表す「Key」とその値の中身を表す「Value」を
Webサーバーに提供される追加の引数のようなもの。なんの値かを表す「Key」とその値の中身を表す「Value」を=記号で結び、複数のパラメーターは&記号で区切られる。
例えば、https://example.com/search?q=hello&lang=ja というURLは、example.com というサイトの search というページに、q というキーに hello という値、lang というキーに ja という値を渡している。
サーバーはこれらの値を見て、hello というキーワードで ja という言語で検索結果を返すように処理する。
アンカー (Anchor)

アンカーは、ページ内の特定の場所を指すために使用される。 基本的にはHTML内のid属性で指定された要素を指す。 サーバーではなく、ブラウザーなどのクライアントが処理する。
例えば、https://developer.mozilla.org/en-US/docs/Learn/Common_questions/Web_mechanics/What_is_a_URL#anchor というURLは、developer.mozilla.org というサイトの What_is_a_URL というページの anchor というアンカーを指している。
ブラウザーはWhat_is_a_URL内のanchorというidを持つ要素を探し、その要素が表示されるように自動でスクロールする。
2つの挙動の違いを実際のページで実感しよう。
#anchorあり
#anchorなし
#anchorあり の方は、自動でスクロールされているのがわかるだろう。
ちなみに、
- 要素: ページを構成する一部分
- ID: 要素に指定できる一意の名前
である。具体的な説明は次章のHTMLの基礎で行う。
参考文献
https://developer.mozilla.org/ja/docs/Learn/Common_questions/Web_mechanics/What_is_a_URL